GPU Poor Savior: Revolutionizing Low-Bit Open Source LLMs and Cost-Effective Edge Computing






from GreenBitAI

Motivation and Background
Since 2010, AI technology has seen several significant advancements, with the rise of deep learning and AlphaGo's notable victory in the Game Go marking significant milestones. The introduction of OpenAI’s ChatGPT in late 2022 highlighted the unprecedented capabilities of large language models (LLMs). Since then, generative AI models have rapidly developed, becoming a vital driver of the fourth industrial revolution, particularly in advancing intelligent and automated technologies in industry upgrades. These technologies transform how we process information, make decisions, and interact, promising profound changes across economic and social dimensions. AI offers significant opportunities; however, the practical application of this technology faces challenges, notably high costs. For instance, the expense of large models during commercialization can be a heavy burden for businesses. Continuous technological breakthroughs are inspiring, but if the costs remain unmanageable, sustaining research and development and gaining widespread trust becomes challenging. However, the rise of large open-source models is gradually changing this scenario. They not only democratize technology by making it more accessible but also promote rapid development by reducing entry barriers. For example, consumer-grade GPUs can now support full-parameter fine-tuning of models up to 7B/8B sizes, potentially at much lower costs than proprietary models. In this decentralized AI paradigm, open-source models can significantly lower marginal costs while the competition ensures quality and speeds up commercialization. Observations also show that larger models, after quantization compression, often outperform equivalently sized smaller pre-trained models, indicating that quantized models retain excellent capabilities, providing a compelling reason to choose open-source models over repetitive pre-training.
In the rapidly evolving field of AI, cloud-based large models are pushing the boundaries of technology to enable broader applications and more robust computing capabilities. However, the market demands quick-to-deploy and fast-growing intelligent applications, leading to the popularity of edge computing with large models—especially medium-sized models like 7B and 13B—known for their cost-effectiveness and adjustability. Businesses prefer fine-tuning these models to ensure stable application performance and ongoing data quality control. Additionally, the feedback mechanism allows data collected from applications to train more efficient models, making continuous data optimization and detailed user feedback a core competitive advantage. Despite the high accuracy of cloud models in handling complex tasks, they face several key challenges:
- Infrastructure costs for inference services: High-performance hardware, particularly GPUs, is scarce and expensive. The incremental marginal costs associated with centralized commercial operations are significant barriers to scaling AI businesses.
- Inference latency: In production environments, models must respond swiftly and deliver results, as any delay can directly impact user experience and application performance. This requires infrastructure capable of efficient operation.
- Privacy and data protection: In scenarios involving sensitive information, using third-party cloud services to process sensitive data can raise privacy and security concerns, limiting cloud model usage.
Given these challenges, edge computing offers an attractive alternative. Running medium-sized models directly on edge devices reduces data transmission latency, enhances response speeds, and helps manage sensitive data locally, boosting data security and privacy. With real-time feedback and iterative updates from proprietary data, AI applications become more efficient and personalized.
Despite numerous innovations in the open-source model and tool ecosystem, several limitations persist. These models and tools often lack optimization for local deployment, limiting their use due to computational power and memory constraints. For instance, even a relatively small 7B model may require up to 60GB of GPU memory (requiring expensive H100/A100 GPUs) for full-parameter fine-tuning. Additionally, the market offers a limited selection of pre-trained small models, with LLM teams often focusing more on expanding model size rather than optimizing smaller models. Moreover, while existing quantization techniques effectively reduce memory use during model deployment, they do not allow for quantized-weight optimization during the fine-tuning process, limiting the ability of developers to use larger models under resource constraints. Developers often hope to also save memory during the fine-tuning process through quantization techniques, a need yet to be effectively met.
Our approach is to address these pain points and contribute significant technological advances to the open-source community. Using Neural Architecture Search (NAS) and the corresponding Post-Training Quantization (PTQ) scheme, we offer over 200 low-bit quantized small models derived from various large model scales, ranging from 110B to 0.5B. These models prioritize accuracy and quality, refreshing the state-of-the-art accuracy for low-bit quantization. Our NAS algorithm also considers the hardware-friendly layout of quantized model parameters, allowing these models to easily adapt to mainstream computational hardware like NVIDIA GPUs and Apple silicon chips, greatly easing developers' work. Moreover, we've introduced the Bitorch Engine, an open-source framework, and the DiodeMix optimizer, explicitly designed for low-bit model training. Developers can directly perform full-parameter supervised fine-tuning and continued training of low-bit quantized models in the quantization space, aligning training and inference representations. This shorter engineering chain substantially enhances efficiency and accelerates model and product iterations. We can achieve full-parameter fine-tuning of the LLaMA-3 8B model on a single GTX 3090 GPU by integrating low-bit weight training technology and low-rank gradient techniques (see Figure 1). Our solution is straightforward and effective, conserving resources and addressing the issue of precision loss in quantized models. We will discuss more technical details in the following sections.
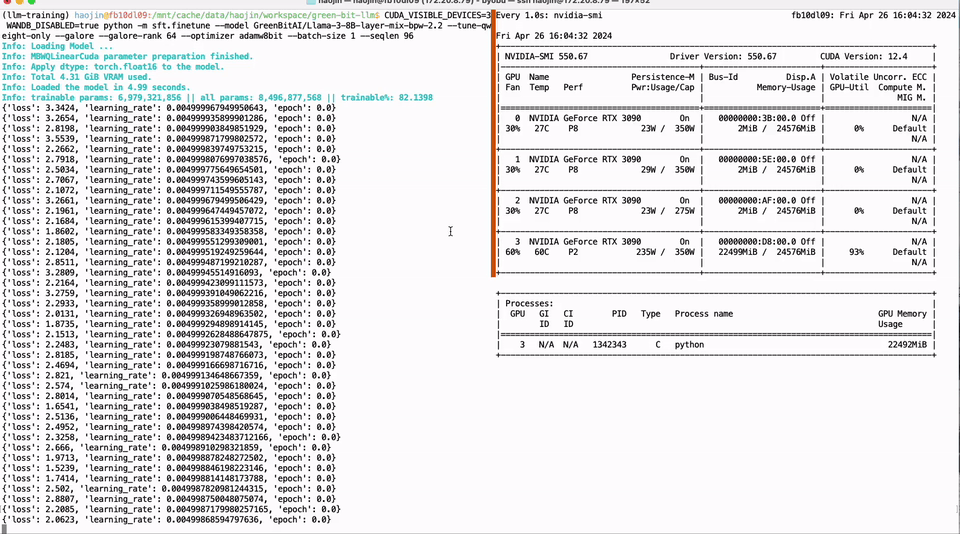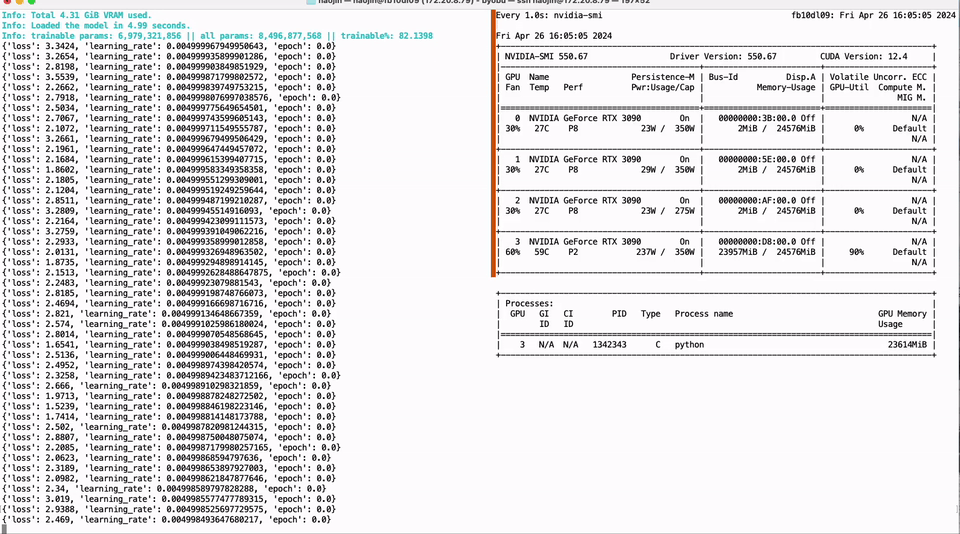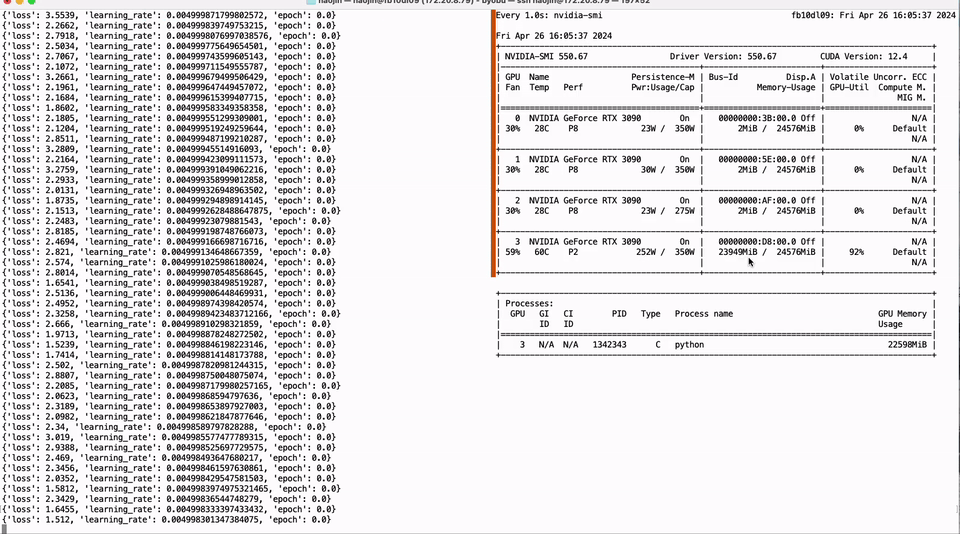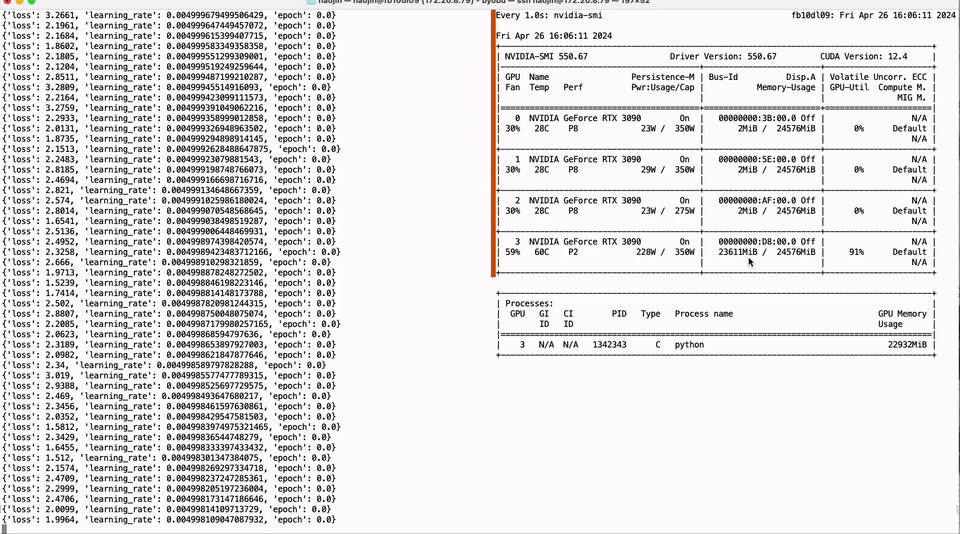 Figure 1. A single GTX 3090 realizes LLaMA-3 8B full parameter fine-tuning.
Figure 1. A single GTX 3090 realizes LLaMA-3 8B full parameter fine-tuning.
Model Quantization
One hallmark of the era of large models is the substantial increase in computational resource demands. Weight Post-Training Quantization (PTQ) compression schemes such as GPTQ and AWQ have proven the reliability of large language models on 4-bit representations. They achieve a fourfold compression of weight space compared to FP16 representations while incurring minimal performance loss, significantly reducing the hardware resources required for model inference. Concurrently, QLoRA ingeniously combines 4-bit LLM representations with LoRA technology, extending low-bit representation to the fine-tuning stage. After fine-tuning, it merges the LoRA module with the original FP16 model, enabling Parameter-Efficient-Finetuning (PEFT) with low resource demands. These cutting-edge engineering explorations provide the community with convenient research tools, significantly lowering the resource barriers for model research and industrial applications and stimulating academic and industrial imaginations toward lower-bit representations.
Compared to INT4, lower-bit Round-To-Nearest (RTN) quantizations like INT2 require the original model to have a smoother continuous parameter space to keep lower quantization losses. For instance, ultra-large-scale models often exhibit capacity redundancy and a higher tolerance for quantization. Recent works, such as LLM.int8(), analyzing current transformer-based large language models, have observed a systemic activation emergence phenomenon during model inference, where a few channels play a decisive role in the final inference outcomes. Recent studies like layer-Importance have further observed that different depths of transformer modules also exhibit a non-uniform distribution in their contribution to model capacity. These characteristics provide insights for low-bit compression. We thus explored a Two-stage LLM low-bit quantization approach that combines searching and calibration.
Firstly, we use NAS-related methods to search and rank the quantization sensitivity of parameter spaces, utilizing classic mixed-precision representations to achieve optimal bit allocation within model parameters. To reduce the complexity, we opted against complex vector quantization and INT3 representations, instead using classic Group-wise MinMax Quantizers. We selected only INT4 (group size 128) and INT2 (group size 64) as our foundational quantization representations. The relatively simple Quantizer design lowers the complexity of computing acceleration kernels and cross-platform deployment challenges. For this purpose, we explored mixed-precision search spaces under Layer-mix and Channel-mix arrangements. Channel-mix quantization, better suited to the systemic activation emergence phenomenon of transformer architectures, often achieves lower quantization losses, while Layer-mix quantization maintains excellent model capacity and hardware friendliness. Using an efficient mixed-precision NAS algorithm, we can complete the quantization layout statistics for a large model like Qwen1.5 110B within a few hours on low-end GPUs like the RTX 3090 and perform optimal architecture searches for any low-bit level model in seconds based on these characteristics. We observed that we can quickly construct robust low-bit models based on searching and importance ranking.
After obtaining the quantization layout from the search, we introduced a scalable PTQ calibration algorithm based on offline knowledge distillation to address the cumulative distribution drift issues brought by ultra-low-bit quantization (such as 2 to 3-bit). With a multi-source calibration dataset of 512 samples, we can complete PTQ calibration for large language models from 0.5B to 110B within a few hours using a single A100 GPU. Although the additional calibration step introduces a longer compression time, based on the experience from classic low-bit and Quantization-Aware Training (QAT) studies, this is a necessary condition for constructing models with low quantization loss. As the continuous emergence of 100B+ large models in the open-source community (such as Command R plus, Qwen1.5 110B, LLama3 400B) continues, building efficient and scalable quantization compression schemes will be an essential part of the LLM-systems engineering research and an ongoing focus of our attention. We empirically demonstrated that a low-bit quantization approach combining search and calibration has significant advantages in advancing model architecture adaptation in the open-source community.
Performance Analysis
Using our Two-stage quantization compression approach, we have developed over 200 low-bit quantized models derived from various open-source LLMs, including the latest series like Llama3, Llama2, Phi-3, Qwen1.5, and Mistral, etc. We employed the EleutherAI lm-evaluation-harness library to explore these low-bit quantized models' real-world performance and industry applications. Our 4-bit quantization calibration scheme achieves lossless compression relative to FP16 representations. The sub-4 bit quantization calibration scheme, implemented using mixed INT4 and INT2 representations, has shown in multiple zero-shot evaluation results that the classic INT2 quantization representation, with minimal data calibration, is sufficient to maintain core capabilities in language model reading comprehension (BoolQ, RACE, ARC-E/C), commonsense reasoning (Winogr, Hellaswag, PIQA), and natural language inference (WIC, ANLI-R1, ANLI-R2, ANLI-R3).
| Zero-Shot Tasks | Phi-3 mini 128k (bpw:2.5/3.0/4.0/16) | Llama 3 8B (bpw:2.5/3.0/4.0) | Qwen1.5 14B (bpw:2.2/2.5/3.0) |
|---|---|---|---|
| PIQA | 0.75/0.77/0.78/0.78 | 0.74/0.76/0.79 | 0.74/0.77/0.78 |
| BoolQ | 0.79/0.80/0.82/0.85 | 0.75/0.78/0.79 | 0.83/0.79/0.83 |
| Winogr. | 0.65/0.66/0.70/0.73 | 0.68/0.70/0.72 | 0.67/0.68/0.69 |
| ARC-E | 0.71/0.76/0.77/0.78 | 0.76/0.77/0.79 | 0.72/0.72/0.73 |
| ARC-C | 0.40/0.45/0.49/0.51 | 0.41/0.44/0.51 | 0.40/0.41/0.42 |
| WiC | 0.49/0.57/0.60/0.59 | 0.51/0.52/0.54 | 0.64/0.62/0.68 |
Table 1. Low-bit quantization model zero-shot evaluation results
Furthermore, we explored the application potential of ultra-low-bit models through few-shot ablation experiments. An interesting finding is that ultra-low-bit models (e.g. bpw: 2.2/2.5), primarily represented in INT2, could revert to the zero-shot inference level of the original FP16 model with the 5-shot assistance. This ability to utilize a small number of exemplary samples indicates that low-bit compression technology is nearing a phase where it can create capable "smart" language models with limited capacity. This is particularly effective when paired with retrieval-augmented technologies such as RAG, making it suitable for creating more cost-effective model services.
| 5-Shot Tasks | Phi-3 mini 128k (bpw:2.5/3.0/4.0/16) | Llama 3 8B (bpw:2.5/3.0/4.0) | Qwen1.5 14B (bpw:2.2/2.5/3.0) |
|---|---|---|---|
| PIQA | 0.76/0.78/0.76/0.76 | 0.75/0.77/0.79 | 0.76/0.79/0.79 |
| BoolQ | 0.79/0.80/0.86/0.86 | 0.79/0.80/0.81 | 0.86/0.84/0.86 |
| Winogr. | 0.67/0.68/0.72/0.72 | 0.70/0.71/0.74 | 0.69/0.71/0.71 |
| ARC-E | 0.77/0.79/0.81/0.82 | 0.77/0.79/0.82 | 0.78/0.81/0.81 |
| ARC-C | 0.44/0.50/0.54/0.53 | 0.44/0.47/0.51 | 0.47/0.50/0.49 |
| WiC | 0.53/0.56/0.65/0.62 | 0.60/0.55/0.59 | 0.64/0.61/0.62 |
Table 2. Low-bit quantization model 5-shot evaluation results
Given that our current few-sample PTQ calibration only introduced limited computational resources (calibration dataset with 512 samples), using our open-source models as a basis for more comprehensive full-parameter fine-tuning will further enhance the performance of low-bit models in practical tasks. We have already provided customized open-source tools to meet this demand efficiently.
Open Source Tools
We have released three tools to support the use of these models and plan to optimize and continually expand them in the future.
Bitorch Engine (BIE)
Bitorch Engine (BIE) is a cutting-edge neural network computation library designed to find the perfect balance between flexibility and efficiency for modern AI research and development. Based on PyTorch, BIE customizes optimized network components for low-bit quantized neural network operations. These components maintain the high precision and accuracy of deep learning models and significantly reduce the consumption of computing resources. It serves as the foundation for full-parameter fine-tuning of low-bit quantized LLMs. Moreover, BIE also offers kernels based on CUTLASS and CUDA, supporting 1-8-bit Quantization-Aware Training. We have also developed an optimizer specifically designed for low-bit components, DiodeMix, which effectively addresses the alignment issues between quantization training and inference representations. During development, we found that PyTorch natively does not support gradient calculations for low-bit tensors, motivating us to make slight modifications to PyTorch to provide a version that supports low-bit gradient calculations, facilitating community use of this feature. Currently, BIE is available for installation via Conda and Docker, with a fully Pip-based pre-compiled installation version that will soon be available to the community for more convenience.
green-bit-llm
green-bit-llm is a toolkit developed for GreenBitAI's low-bit LLMs. This toolkit supports high-performance inference on cloud and consumer GPUs and, in conjunction with Bitorch Engine, supports direct use of quantized LLMs for full-parameter fine-tuning and PEFT. It is already compatible with several low-bit model series, as detailed in Table 3.
| LLMs | Type | Bits | Size | HF Link |
|---|---|---|---|---|
| Llama-3 | Base/Instruct | 4.0/3.0/2.5/2.2 | 8B/70B | GreenBitAI Llama-3 |
| Llama-2 | Base/Instruct | 3.0/2.5/2.2 | 7B/13B/70B | GreenBitAI Llama-2 |
| Qwen-1.5 | Base/Instruct | 4.0/3.0/2.5/2.2 | 0.5B/1.8B/4B/7B/14B/32B/110B | GreenBitAI Qwen 1.5 |
| Phi-3 | Instruct | 4.0/3.0/2.5/2.2 | mini | GreenBitAI Phi-3 |
| Mistral | Base/Instruct | 3.0/2.5/2.2 | 7B | GreenBitAI Mistral |
| 01-Yi | Base/Instruct | 4.0/3.0/2.5/2.2 | 6B/9B/34B | GreenBitAI 01-Yi |
Table 3. Supported low-bit LLMs
Let's use the latest Llama-3 8b base as an example. We chose to perform Quantized Supervised Fine-Tuning (Q-SFT) on it using 2.2/2.5/3.0-bit precision, focusing on the entire parameter set. We used the "tatsu-lab/alpaca" dataset hosted on the Hugging Face, which contains 52,000 training dialogue samples. The model was trained over one epoch with minimal instruction fine-tuning, aligning strictly within the quantized weight space without engaging in conventional post-processing steps like LoRA parameter optimization and integration. After training, the model can be deployed directly for inference without updating any other FP16 parameters, thus validating the effectiveness of quantized learning. The impacts of Q-SFT, both before and after, as well as classic LoRA fine-tuning on model capabilities, are shown in Table 4.
| 0-Shot Tasks | Base (bpw 2.2/2.5/3.0) | LoRA (bpw 2.2/2.5/3.0) | Q-SFT + Galore (bpw 2.2/2.5/3.0) | Q-SFT (bpw 2.2/2.5/3.0) |
|---|---|---|---|---|
| PIQA | 0.72/0.74/0.76 | 0.75/0.77/0.78 | 0.75/0.76/0.78 | 0.75/0.76/0.79 |
| BoolQ | 0.74/0.75/0.78 | 0.77/0.76/0.80 | 0.77/0.76/0.79 | 0.78/0.78/0.80 |
| Winogr. | 0.67/0.68/0.70 | 0.68/0.69/0.71 | 0.68/0.69/0.71 | 0.67/0.69/0.72 |
| ARC-E | 0.73/0.76/0.77 | 0.77/0.77/0.79 | 0.76/0.77/0.79 | 0.75/0.76/0.79 |
| ARC-C | 0.39/0.41/0.44 | 0.46/0.44/0.49 | 0.45/0.43/0.47 | 0.45/0.43/0.49 |
| WiC | 0.50/0.51/0.52 | 0.50/0.50/0.52 | 0.50/0.52/0.57 | 0.50/0.51/0.60 |
| Avg | 0.62/0.64/0.66 | 0.65/0.65/0.68 | 0.65/0.65/0.68 | 0.65/0.65/0.69 |
Table 4. The impact of Q-SFT on the zero-shot capability
In addition to our low-bit models, green-bit-llm is fully compatible with the AutoGPTQ series of 4-bit quantization and compression models. This means that all 2,848 existing 4-bit GPTQ models on Hugging Face can be further trained or fine-tuned with low resources in the quantized parameter space using green-bit-llm. As one of the most popular compression formats in the LLM deployment ecosystem, existing AutoGPTQ enthusiasts can seamlessly switch between model training and inference using green-bit-llm without introducing new engineering steps.
Our innovative DiodeMix optimizer, specifically designed for low-bit models, is key to the stable operation of Q-SFT in low-resource settings. This optimizer helps mitigate the mismatch between FP16 gradients and quantized spaces. The quantized parameter update process cleverly transforms into a sorting issue based on the relative sizes of cumulative gradients between param-groups. Developing optimizers that are more aligned with quantized parameter spaces will be an essential direction for our ongoing research.
gbx-lm
gbx-lm adapts GreenBitAI's low-bit models to Apple's MLX framework, enabling efficient operation of large models on Apple chips. It currently supports basic operations such as model loading, generation, and LoRA finetuning. Additionally, the tool provides a demo illustrating that following our detailed guide, users can quickly establish a local chat demonstration page on an Apple device.
 Figure 2. Chatting with Web demo on MacBook with gbx-lm engine.
Figure 2. Chatting with Web demo on MacBook with gbx-lm engine.
Concluding remarks
We look forward to driving the development of the open-source community together with more developers. If you are passionate about this and wish to advance with like-minded peers, do not hesitate! We sincerely welcome you to join us. You can contact us through community platforms or directly by emailing [email protected].
Links:
- Model Zoo: GreenBitAI
- BIE: bitorch-engine
- green-bit-llm: green-bit-llm
- gbx-lm: gbx-lm


