---
language:
- en
pipeline_tag: text-generation
tags:
- nvidia
- chatqa-2
- chatqa
- llama-3
- pytorch
---
## Model Details
We introduce Llama3-ChatQA-2, a suite of 128K long-context models, which bridges the gap between open-source LLMs and leading proprietary models (e.g., GPT-4-Turbo) in long-context understanding and retrieval-augmented generation (RAG) capabilities. Llama3-ChatQA-2 is developed using an improved training recipe from [ChatQA-1.5 paper](https://arxiv.org/pdf/2401.10225), and it is built on top of [Llama-3 base model](https://huggingface.co/meta-llama/Meta-Llama-3-70B). Specifically, we continued training of Llama-3 base models to extend the context window from 8K to 128K tokens, along with a three-stage instruction tuning process to enhance the model’s instruction-following, RAG performance, and long-context understanding capabilities. Llama3-ChatQA-2 has two variants: Llama3-ChatQA-2-8B and Llama3-ChatQA-2-70B. Both models were originally trained using [Megatron-LM](https://github.com/NVIDIA/Megatron-LM), we converted the checkpoints to Hugging Face format. **For more information about ChatQA 2, check the [website](https://chatqa2-project.github.io/)!**
## Other Resources
[Llama3-ChatQA-2-8B](https://huggingface.co/nvidia/Llama3-ChatQA-2-8B) [Evaluation Data](https://huggingface.co/nvidia/Llama3-ChatQA-2-70B/tree/main/data) [Training Data](https://huggingface.co/datasets/nvidia/ChatQA2-Long-SFT-data) [Website](https://chatqa2-project.github.io/) [Paper](https://arxiv.org/abs/2407.14482)
## Overview of Benchmark Results
We evaluate ChatQA 2 on short-context RAG benchmark (ChatRAG) (within 4K tokens), long context tasks from SCROLLS and LongBench (within 32K tokens), and ultra-long context tasks from In- finiteBench (beyond 100K tokens). Results are shown below.
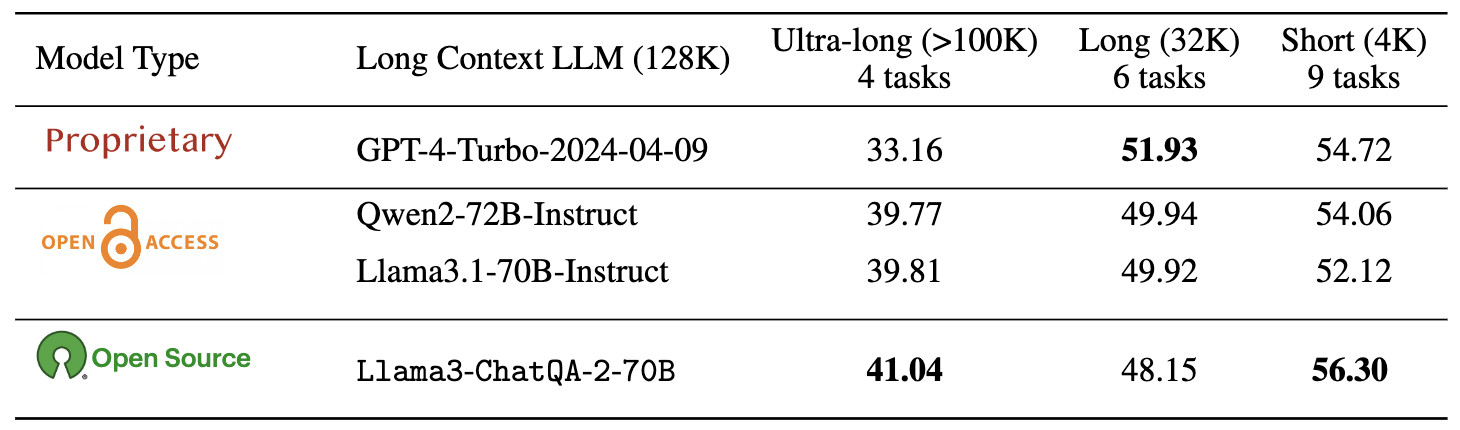
Note that ChatQA-2 is built based on Llama-3 base model.
## Prompt Format
**We highly recommend that you use the prompt format we provide, as follows:**
### when context is available
System: {System}
{Context}
User: {Question}
Assistant: {Response}
User: {Question}
Assistant:
### when context is not available
System: {System}
User: {Question}
Assistant: {Response}
User: {Question}
Assistant:
**The content of the system's turn (i.e., {System}) for both scenarios is as follows:**
This is a chat between a user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions based on the context. The assistant should also indicate when the answer cannot be found in the context.
**Note that our ChatQA-2 models are optimized for the capability with context, e.g., over documents or retrieved context.**
## How to use
### take the whole document as context
This can be applied to the scenario where the whole document can be fitted into the model, so that there is no need to run retrieval over the document.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "nvidia/Llama3-ChatQA-2-8B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")
messages = [
{"role": "user", "content": "what is the percentage change of the net income from Q4 FY23 to Q4 FY24?"}
]
document = """NVIDIA (NASDAQ: NVDA) today reported revenue for the fourth quarter ended January 28, 2024, of $22.1 billion, up 22% from the previous quarter and up 265% from a year ago.\nFor the quarter, GAAP earnings per diluted share was $4.93, up 33% from the previous quarter and up 765% from a year ago. Non-GAAP earnings per diluted share was $5.16, up 28% from the previous quarter and up 486% from a year ago.\nQ4 Fiscal 2024 Summary\nGAAP\n| $ in millions, except earnings per share | Q4 FY24 | Q3 FY24 | Q4 FY23 | Q/Q | Y/Y |\n| Revenue | $22,103 | $18,120 | $6,051 | Up 22% | Up 265% |\n| Gross margin | 76.0% | 74.0% | 63.3% | Up 2.0 pts | Up 12.7 pts |\n| Operating expenses | $3,176 | $2,983 | $2,576 | Up 6% | Up 23% |\n| Operating income | $13,615 | $10,417 | $1,257 | Up 31% | Up 983% |\n| Net income | $12,285 | $9,243 | $1,414 | Up 33% | Up 769% |\n| Diluted earnings per share | $4.93 | $3.71 | $0.57 | Up 33% | Up 765% |"""
def get_formatted_input(messages, context):
system = "System: This is a chat between a user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions based on the context. The assistant should also indicate when the answer cannot be found in the context."
instruction = "Please give a full and complete answer for the question."
for item in messages:
if item['role'] == "user":
## only apply this instruction for the first user turn
item['content'] = instruction + " " + item['content']
break
conversation = '\n\n'.join(["User: " + item["content"] if item["role"] == "user" else "Assistant: " + item["content"] for item in messages]) + "\n\nAssistant:"
formatted_input = system + "\n\n" + context + "\n\n" + conversation
return formatted_input
formatted_input = get_formatted_input(messages, document)
tokenized_prompt = tokenizer(tokenizer.bos_token + formatted_input, return_tensors="pt").to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(input_ids=tokenized_prompt.input_ids, attention_mask=tokenized_prompt.attention_mask, max_new_tokens=128, eos_token_id=terminators)
response = outputs[0][tokenized_prompt.input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
```
## Command to run generation
```
python evaluate_cqa_vllm_chatqa2.py --model-folder ${model_path} --eval-dataset ${dataset_name} --start-idx 0 --end-idx ${num_samples} --max-tokens ${max_tokens} --sample-input-file ${dataset_path}
```
see all_command.sh for all detailed configuration.
## Correspondence to
Peng Xu (pengx@nvidia.com), Wei Ping (wping@nvidia.com)
## Citation
@article{xu2024chatqa,
title={ChatQA 2: Bridging the Gap to Proprietary LLMs in Long Context and RAG Capabilities},
author={Xu, Peng and Ping, Wei and Wu, Xianchao and Liu, Zihan and Shoeybi, Mohammad and Catanzaro, Bryan},
journal={arXiv preprint arXiv:2407.14482},
year={2024}
}
## License
The Model is released under Non-Commercial License and the use of this model is also governed by the [META LLAMA 3 COMMUNITY LICENSE AGREEMENT](https://llama.meta.com/llama3/license/)